Building a Minimal RAG Model
Large language models (LLMs) like ChatGPT are very good at generating cohesive text on a wide range of topics. Often, however, we want to generate text for a very specific use case. For example, imagine we want a model that is able to answer factual questions about historical financial data. When we ask ChatGPT the question “What was the inflation rate in Indonesia in 1986?”, it states that it doesn’t have enough information to provide a good answer. Other LLMs might give a reasonable looking, but factually inaccurate, answer as LLMs can be prone to hallucinations.

If we want to build a model that can answer questions like this we have a couple of options. We could fine-tune an LLM on a dataset of questions and answers, but this requires a lot of data, can be expensive, and we may lose some generality in the text the LLM can generate. Alternatively, we could augment the model with external tools or resources.
RAG models (retrieval augmented generation) aim to augment language models by providing them with additional context with which to respond to a user query. Originally designed to include a training loop, RAG models now tend more towards stitching together pre-trained components with a vector database. The below figure (which is taken from a more detailed tutorial on building RAG models at scale) shows the main components and structure of a RAG model.
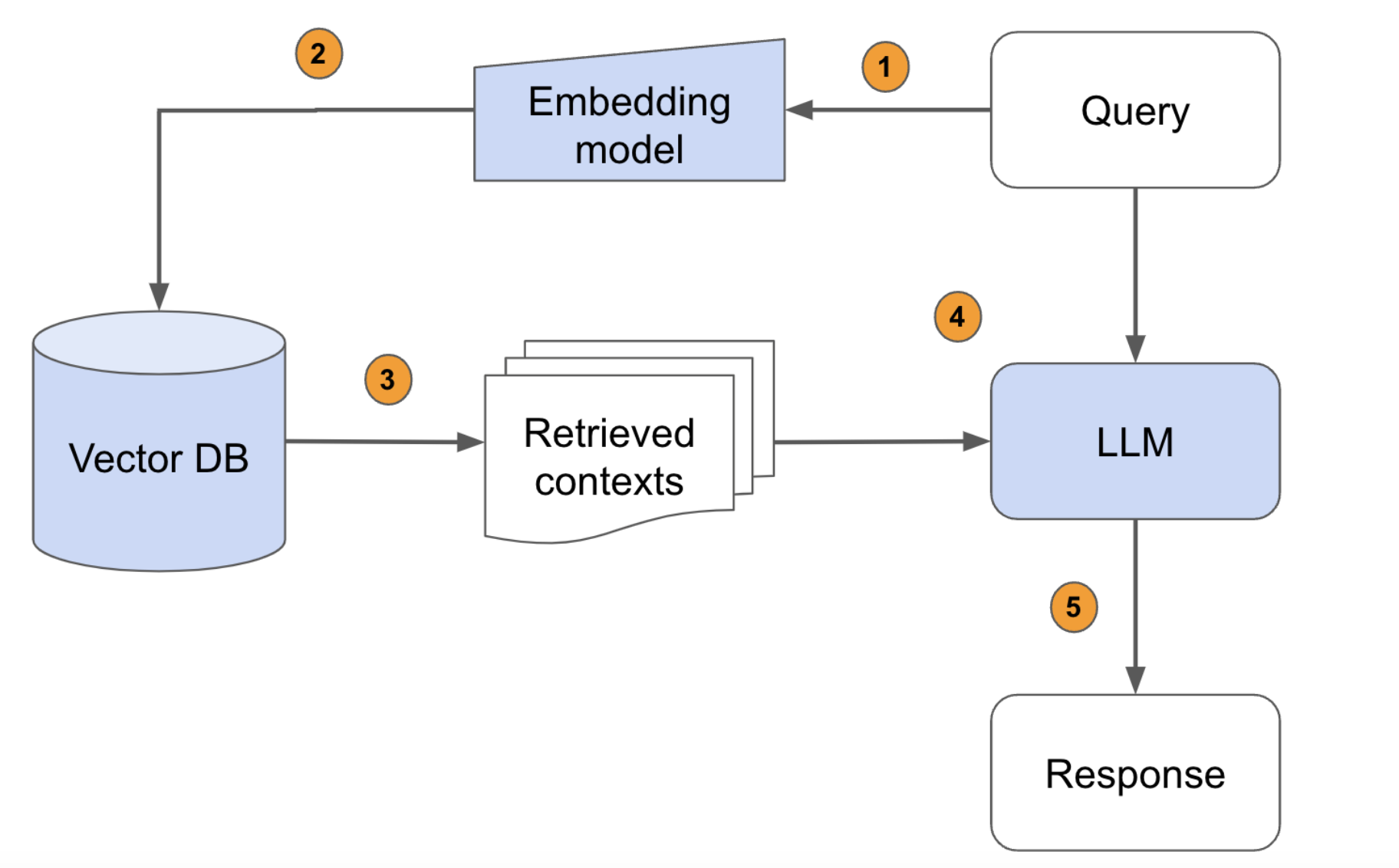
- Set-Up: A vector database (VectorDB) is created offline by embedding relevant resources/documents using a pre-trained language embedding model that converts text to vector embeddings.
- Step One: A user query is received and embedded with the same embedding model used to create the VectorDB
- Step Two: The VectorDB is searched to find the document(s) with the most similar embedding(s). (Using cosine similarity, L2 distance or similar.)
- Step Three: The documents retrieved from the VectorDB are added to the user’s query as additional context.
- Step Four: The original query augmented with the documents is fed into an LLM.
- Step Five: The LLM should now generate a more reasonable response using the additional information from an outside source.
Spinning Up a Minimal Example
To see what this actually looks like in practice, we will walk through how to build a very simple RAG model making use of available tools. The documents we embed to create the VectorDB are a small number of news documents from the nltk reuters corpus. To build the VectorDB we use ChromaDB which allows to create a locally stored vector database with a few lines of code. We use the OpenAI API to access powerful models for embedding documents and generating text.
Creating a VectorDB
A VectorDB is just a database where each entry haa a vector associated with it allowing us to search the database to find the entry with the closest vector. To keep costs low, for this example we will take the first 100 documents from the nltk reuters corpus and discard any documents with more than 500 words. Returning to our original example on Indonesian inflation, one of the documents in this set is shown below. We can see how if we are able to provide this context to the LLM we should be able to get a good answer to our question about past inflation rates in Indonesia.

First, we set up a method to embed documents using the OpenAI text-embedding-ada-002 model.
import openai
from chromadb.utils import embedding_functions
def get_embedding_function():
openai_ef = embedding_functions.OpenAIEmbeddingFunction(
api_key=get_openai_key(),
model_name="text-embedding-ada-002"
)
return openai_ef
With this embedding function, the below code creates a locally stored VectorDB which stores the raw text of the reuters documents, an id for each document and the vector created by the embedding model.
import chromadb
import nltk
from nltk.corpus import reuters
from utils import get_embedding_function
nltk.download('reuters')
reuters_subset = reuters.fileids()[0:100]
reuters_subset = [id for id in reuters_subset if len(reuters.words(id)) < 500]
client = chromadb.PersistentClient(path="chromadb/test_db")
collection = client.create_collection(name="reuters_collection", embedding_function=get_embedding_function())
for i, file_id in enumerate(reuters_subset):
collection.add(
documents=[reuters.raw(file_id)],
metadatas=[{"nltk_file_id": file_id}],
ids=[str(i)]
)
print(collection.peek()) # To see the first documents in the collection
Building a RAG model
Now we have constructed our VectorDB to store relevant documents, when we receive a user query we query the VectorDB, get the top 3 most similar results, and then add the top 3 results to the user query to generate a response. In the below code get_rag_context embeds the user query and finds the most similar 3 documents to use as additional context. The method rag_response gets a response from the LLM (gpt-3.5-turbo) when these documents are provided alongside the query. For comparison the method response gets a response using only the user query with no additional information.
import openai
import chromadb
from utils import get_embedding_function
def response(query):
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": f"{query}"},
]
)
return response['choices'][0]['message']['content']
def rag_response(query, context):
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "You are a helpful assistant. Please answer the query using the context provided."},
{"role": "user", "content": f"query: {query}. context: {context}"},
]
)
return response['choices'][0]['message']['content']
def get_rag_context(query, client, num_docs=3):
collection = client.get_collection(name="reuters_collection", embedding_function=get_embedding_function())
results = collection.query(
query_texts=[query],
n_results=num_docs
)
contexts = [doc.replace("\n", " ") for doc in results['documents'][0]]
return contexts
def main():
client = chromadb.PersistentClient(path="../chromadb/test_db")
query = "What was the inflation rate in Indonesia in 1986?"
contexts = get_rag_context(query, client)
default_response = response(query)
ragged_response = rag_response(query, ";".join(contexts))
print(f"Query: {query}")
print(f"Default response: {default_response}")
print(f"RAG response: {ragged_response}")
if __name__ == "__main__":
main()
RAG in action
Now we can see what happens when we ask the RAG model our original question about the inflation rate in Indonesia in 1986. We see here that with the additional context the LLM is able to answer the question with the correct answer (8.8%) whereas the default LLM without augmented context is unable to provide a definitive answer.

Summary
In around 100 lines of code we have augmented a large language model to use external resources when answering user queries. We have seen that with the right additional context LLMs are able to better answer specific technical questions.
This simple code is only possible because of recent improvements in the tooling available for building these models. We can query large models in a few lines of code with the OpenAI API and build a VectorDB quickly with ChromaDB. Recently, OpenAI have even launched a beta for their Assistants API where you can use retrieval without ever leaving the OpenAI ecosystem.
RAG models are a useful tool for building applications with LLMs right now. However, despite the release of GPT-4 which is bigger and better than GPT-3.5 used here, hallucinations and inability to answer factual questions still remain a problem. Whether RAG-style approaches will lead to more general AI systems I am less sure, currently I tend to lean more towards scaling self-prediction in end-to-end systems.
Code
A repository containing the minimal RAG model discussed in this post can be found here.